building a multi-llm plan critique system for claude code
Version history
- v3Replaced v1/v2 hooks with superpowers skills + codex review gate
- v2.1Added auto-save to thoughts/research/, prompted save to plans/
- v2Added council planning (parallel brainstorming)
- v1Original sequential critique system
one model has blind spots. always. i've watched gemini catch architectural issues codex missed, and codex catch edge cases gemini glossed over. when they disagree, that's signal.
this is a deep dive into how i built a claude code hook that sends plans through multiple llms before implementation starts.

v3: the custom hooks from v1 and v2 have been replaced by superpowers — a skill system that handles brainstorming, planning, verification, and code review natively inside claude code. it's better than what i built. on top of that, i've added the codex review gate as a stop-time quality check. skip to the current setup for what i actually use now.
the insight
i was using multiple llms to critique plans. claude writes a plan, then i send it to gemini and codex for review. it works.
but i realized i was doing it wrong.
the problem: reviewers only see the finished plan. they can't offer alternative approaches they might have discovered if they'd explored the problem themselves.
it's like asking someone to review your code after you've already written it. they can spot bugs, but they can't suggest a fundamentally different architecture. that ship has sailed.
post-critique = code review (valuable, but late) parallel planning = brainstorming session (early, diverse perspectives)
both have their place. here's how to build each.
v1: sequential critique
the original approach. claude plans, then others review.
the goal
when claude creates an implementation plan, i want:
- test-first enforcement. block if no test files listed
- gemini 3 flash critique. architectural review, coverage gaps
- codex second opinion. what did gemini miss?
- all feedback visible to claude before implementation starts
how claude code hooks work
hooks are commands that run at specific points in claude's workflow. the one i care about is PostToolUse. runs after a tool completes.
in ~/.claude/settings.json:
{
"hooks": {
"PostToolUse": [
{
"matcher": "ExitPlanMode",
"hooks": [
{
"type": "command",
"command": "~/.claude/hooks/critique-plan.sh",
"timeout": 600
}
]
}
]
}
}
this triggers my script whenever claude exits plan mode (i.e., the plan is ready for approval).
the architecture
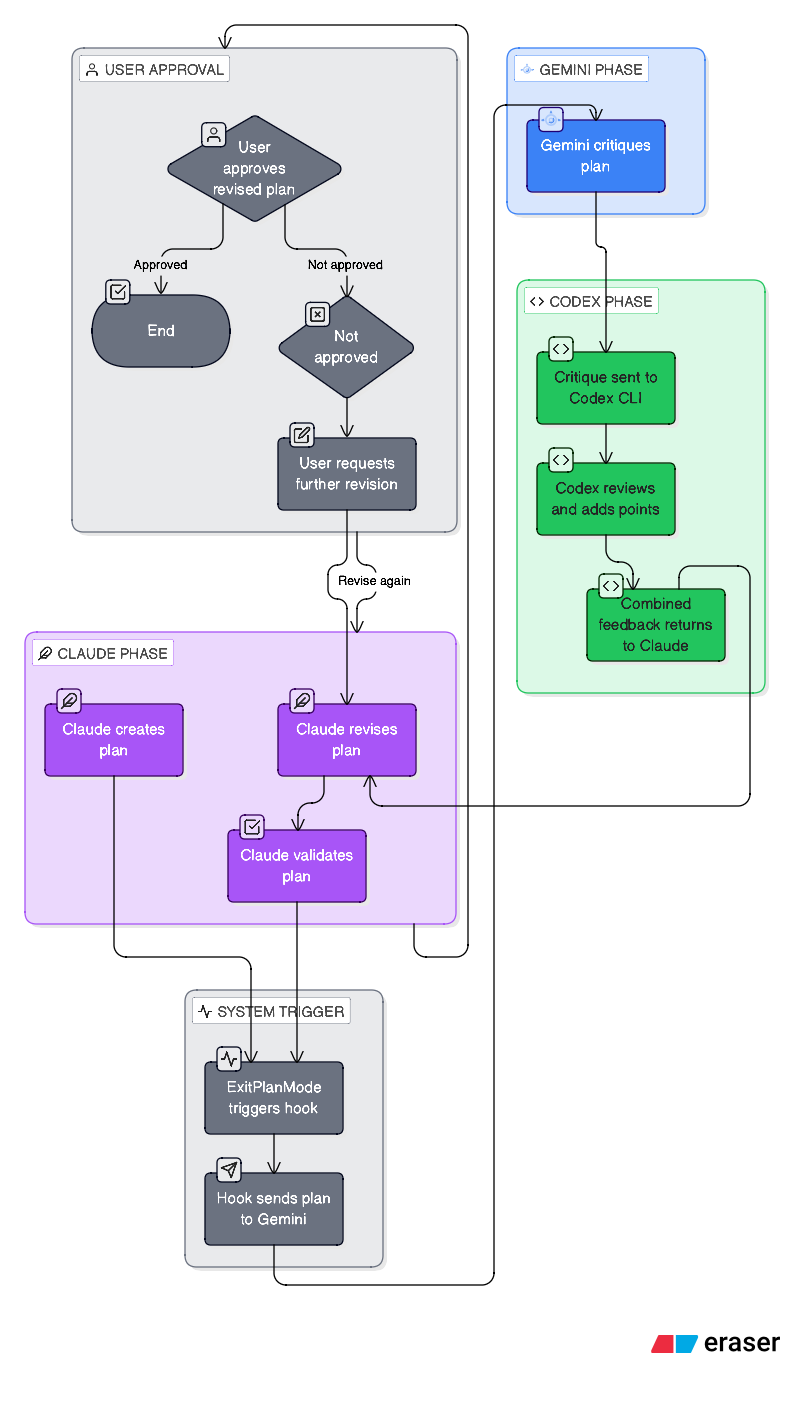

the hard parts
problem 1: blocking doesn't work with json
my first attempt returned:
{
"decision": "block",
"reason": "TEST-FIRST VIOLATION: Plan rejected..."
}
claude code said "hook succeeded" and kept going. the decision: block was ignored.
fix: use exit code 2 + stderr instead:
# this gets ignored
cat << EOF
{"decision": "block", "reason": "..."}
EOF
exit 0
# this actually blocks
cat >&2 << EOF
TEST-FIRST VIOLATION - Plan Rejected
...
EOF
exit 2
exit code 2 signals "hook blocked this action" and stderr content becomes the message claude sees.
problem 2: background processes are useless
i tried running the llm critiques in the background:
( ... gemini ... codex ... ) &
hook returned immediately. critique ran in the background. claude never saw it because the hook was already done.
fix: make it synchronous. yes, it takes 20-30 seconds. worth it.
# blocking - claude waits and sees the result
GEMINI_RESULT=$(opencode run -m "openrouter/google/gemini-3-flash-preview" "$PROMPT")
CODEX_RESULT=$(codex exec --full-auto "$PROMPT")
problem 3: plan freshness
the hook reads the most recent plan file from ~/.claude/plans/. but if the user takes too long reviewing, the plan gets "stale" and the hook silently exits:
Plan age: 288s (max 120s)
EXIT: Plan too old
claude sees "hook succeeded" and proceeds.
partial fix: increased timeout to 600s. better fix would be reading from tool_response.plan in the hook input instead of relying on file timestamps.
the code
here's the main hook script. it's messy but it works.
#!/bin/bash
set -euo pipefail
DEBUG_LOG="$HOME/.claude/logs/critique-hook.log"
mkdir -p "$(dirname "$DEBUG_LOG")"
log_debug() {
echo "[$(date '+%Y-%m-%d %H:%M:%S')] $1" >> "$DEBUG_LOG"
}
# find most recent plan file
PLAN_FILE=$(ls -t ~/.claude/plans/*.md 2>/dev/null | head -1)
if [[ ! -f "$PLAN_FILE" ]]; then
exit 0 # no plan, nothing to do
fi
# freshness check
PLAN_AGE=$(($(date +%s) - $(stat -f %m "$PLAN_FILE")))
if [[ $PLAN_AGE -gt 600 ]]; then
exit 0 # too old, skip
fi
PLAN_CONTENT=$(cat "$PLAN_FILE")
# test-first check (separate script)
TEST_CHECK=$(echo "$PLAN_CONTENT" | ~/.claude/hooks/test-first-check.sh)
TEST_PASSED=$(echo "$TEST_CHECK" | jq -r '.passed')
if [[ "$TEST_PASSED" == "false" ]]; then
ISSUES=$(echo "$TEST_CHECK" | jq -r '.issues | join("\n- ")')
cat >&2 << EOF
TEST-FIRST VIOLATION - Plan Rejected
Issues:
- $ISSUES
Fix: Add test files BEFORE implementation files in your plan.
EOF
exit 2
fi
# gemini critique
GEMINI_PROMPT="You are a senior architect reviewing an implementation plan...
$PLAN_CONTENT"
GEMINI_RESULT=$(opencode run -m "openrouter/google/gemini-3-flash-preview" "$GEMINI_PROMPT" 2>/dev/null || echo "[unavailable]")
# codex reviews gemini's critique
CODEX_PROMPT="Review this plan AND Gemini's critique. What did Gemini miss?
---
PLAN:
$PLAN_CONTENT
---
GEMINI'S CRITIQUE:
$GEMINI_RESULT"
CODEX_RESULT=$(codex exec --full-auto "$CODEX_PROMPT" 2>/dev/null || echo "[unavailable]")
# return to claude
FULL_CRITIQUE="PLAN CRITIQUE FROM GEMINI + CODEX
## Gemini 3 Flash
$GEMINI_RESULT
## Codex
$CODEX_RESULT"
jq -n --arg ctx "$FULL_CRITIQUE" '{
"hookSpecificOutput": {
"hookEventName": "PostToolUse",
"additionalContext": $ctx
}
}'
what the critiques look like
here's an actual critique from a recent plan:
gemini:
Test Coverage (PRIMARY CRITIQUE - INSUFFICIENT) While the plan includes
collection-viewer.test.ts, it has significant gaps:
- Missing Add Page Tests: You modify
src/app/collection/[id]/add/page.tsxbut provide no corresponding test file.- Null Safety:
currentAndeeTagcan now benull. Tests must verify sub-components don't crash.
codex:
- Missed test scenario:
?viewer=present butuseCurrentAndeereports authenticated; ensure viewer override wins- Test quality issue:
page.test.tsxusesvi.mockinside tests; this won't rewire imports after module is loaded
they catch different things. that's the point.
v2: council planning
the problem with post-plan critique
v1 reviewers only see the finished plan. they can spot flaws in claude's logic, but they can't offer alternative approaches they might have discovered if they'd explored the problem themselves.
it's like asking someone to review your design doc after you've already committed to the architecture. they can poke holes, but the frame is set. they're optimizing within your solution space.
the insight
what if all three models explored the problem independently and in parallel?
each model has different:
- training data
- biases and blind spots
- knowledge of libraries and patterns
when they converge on the same approach: high confidence. when they diverge: you've found the real design decisions.
the architecture
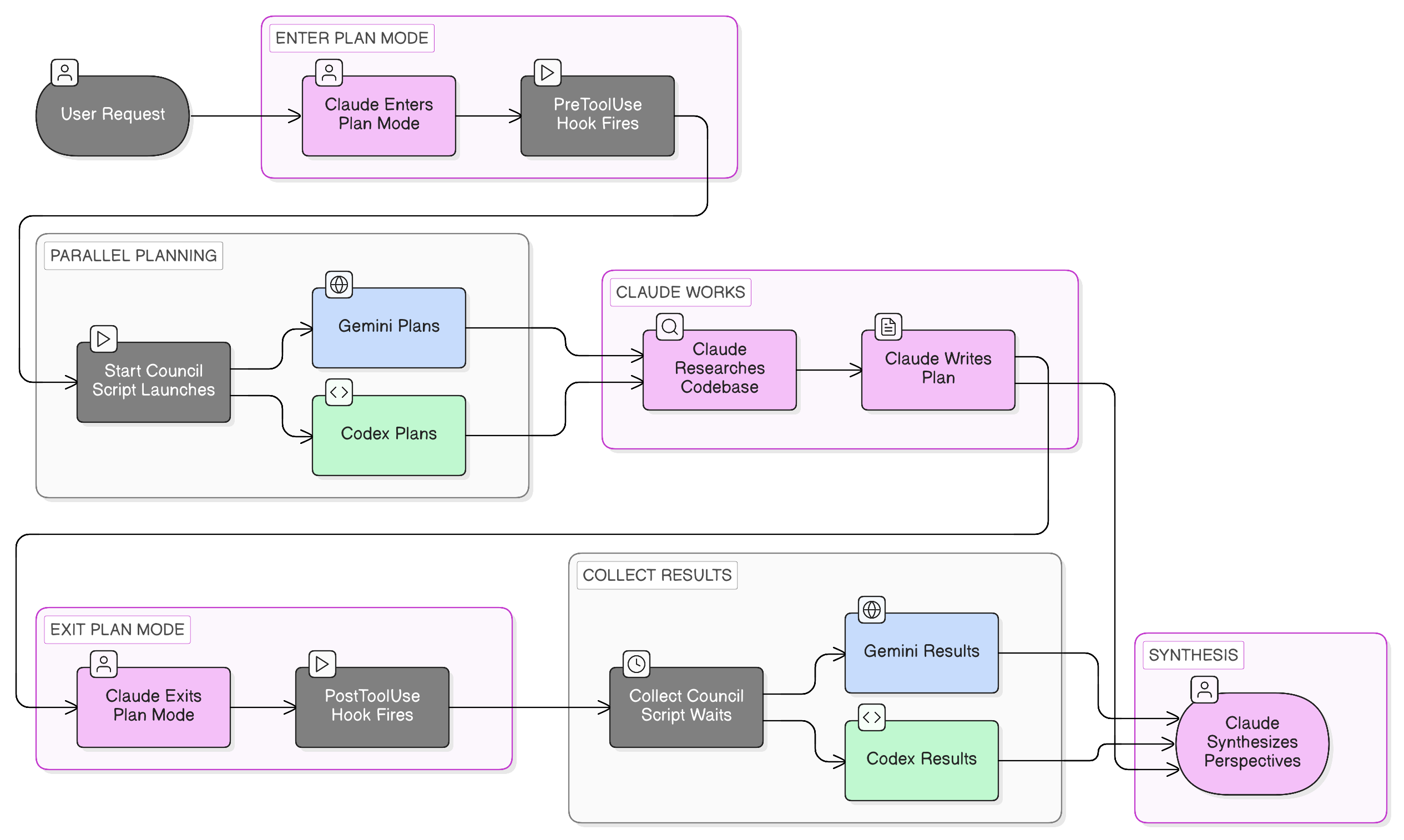

two ways to use it
1. explicit: /council command
/council implement OAuth2 authentication for the API
runs all three models in parallel. claude synthesizes.
2. automatic: hooks on plan mode
when claude enters plan mode naturally, hooks fire:
PreToolUse[EnterPlanMode] → start-council.sh
- Extracts user's request from transcript
- Launches Gemini + Codex in background
- They plan while Claude researches
PostToolUse[ExitPlanMode] → collect-council.sh
- Waits for background processes (2min timeout)
- Injects their plans into Claude's context
- Claude sees other perspectives before finalizing
you don't have to do anything. just use plan mode. council happens automatically.
key insight: non-blocking start, blocking collect. council starts immediately when planning begins. they work in parallel with claude. when claude finishes, we wait for results.
the hooks configuration
{
"hooks": {
"PreToolUse": [
{
"matcher": "EnterPlanMode",
"hooks": [
{
"type": "command",
"command": "\"$CLAUDE_PROJECT_DIR\"/.claude/hooks/start-council.sh",
"timeout": 10
}
]
}
],
"PostToolUse": [
{
"matcher": "ExitPlanMode",
"hooks": [
{
"type": "command",
"command": "\"$CLAUDE_PROJECT_DIR\"/.claude/hooks/collect-council.sh",
"timeout": 180
}
]
}
]
}
}
key details:
PreToolUsewithmatcher: "EnterPlanMode"fires when claude is about to enter plan modePostToolUsewithmatcher: "ExitPlanMode"fires when claude exits plan mode- the collect hook has 180s timeout because we're waiting for background processes
start-council.sh
#!/bin/bash
set -e
SCRATCH_DIR="$CLAUDE_PROJECT_DIR/thoughts/scratch/council"
mkdir -p "$SCRATCH_DIR"
# Read hook input from stdin (JSON)
INPUT=$(cat)
# Get transcript path to extract user's request
TRANSCRIPT_PATH=$(echo "$INPUT" | jq -r '.transcript_path // empty')
if [ -z "$TRANSCRIPT_PATH" ] || [ ! -f "$TRANSCRIPT_PATH" ]; then
exit 0
fi
# Extract last user message from transcript (JSONL format)
LAST_USER_MSG=$(tac "$TRANSCRIPT_PATH" | grep -m1 '"type":"human"' | jq -r '.message.content // empty')
if [ -z "$LAST_USER_MSG" ]; then
exit 0
fi
# Create council request
cat > "$SCRATCH_DIR/request.md" << EOF
# Planning Request
## Task
$LAST_USER_MSG
## Instructions
Create a detailed implementation plan. Include:
1. Approach and rationale
2. Key files to modify/create
3. Step-by-step implementation
4. Potential risks or edge cases
5. Testing strategy
EOF
# Launch Gemini in background
(
opencode run --model openrouter/google/gemini-2.5-pro \
"$(cat "$SCRATCH_DIR/request.md")" \
> "$SCRATCH_DIR/gemini.md" 2>&1
) &
echo $! > "$SCRATCH_DIR/gemini.pid"
# Launch Codex in background
(
codex exec \
"$(cat "$SCRATCH_DIR/request.md")" \
> "$SCRATCH_DIR/codex.md" 2>&1
) &
echo $! > "$SCRATCH_DIR/codex.pid"
echo "Council started: Gemini and Codex planning in background"
exit 0
collect-council.sh
#!/bin/bash
set -e
SCRATCH_DIR="$CLAUDE_PROJECT_DIR/thoughts/scratch/council"
RESEARCH_DIR="$CLAUDE_PROJECT_DIR/thoughts/research"
# Check if council was started
if [ ! -f "$SCRATCH_DIR/gemini.pid" ]; then
exit 0
fi
# Wait for background processes (with timeout)
TIMEOUT=120
WAITED=0
for MODEL in gemini codex; do
PID_FILE="$SCRATCH_DIR/$MODEL.pid"
if [ -f "$PID_FILE" ]; then
PID=$(cat "$PID_FILE")
while kill -0 "$PID" 2>/dev/null && [ $WAITED -lt $TIMEOUT ]; do
sleep 2
WAITED=$((WAITED + 2))
done
kill -9 "$PID" 2>/dev/null || true
fi
done
# Auto-save raw perspectives to research/ for future reference
mkdir -p "$RESEARCH_DIR"
TIMESTAMP=$(date +%Y-%m-%d_%H-%M)
if [ -f "$SCRATCH_DIR/gemini.md" ] && [ -s "$SCRATCH_DIR/gemini.md" ]; then
cp "$SCRATCH_DIR/gemini.md" "$RESEARCH_DIR/${TIMESTAMP}_gemini.md"
fi
if [ -f "$SCRATCH_DIR/codex.md" ] && [ -s "$SCRATCH_DIR/codex.md" ]; then
cp "$SCRATCH_DIR/codex.md" "$RESEARCH_DIR/${TIMESTAMP}_codex.md"
fi
# Output council results to Claude's context
echo ""
echo "=== COUNCIL RESULTS ==="
echo ""
if [ -f "$SCRATCH_DIR/gemini.md" ] && [ -s "$SCRATCH_DIR/gemini.md" ]; then
echo "### Gemini's Plan"
echo ""
cat "$SCRATCH_DIR/gemini.md"
echo ""
fi
if [ -f "$SCRATCH_DIR/codex.md" ] && [ -s "$SCRATCH_DIR/codex.md" ]; then
echo "### Codex's Plan"
echo ""
cat "$SCRATCH_DIR/codex.md"
echo ""
fi
echo "=== END COUNCIL ==="
echo ""
echo "Consider the above perspectives when finalizing your plan."
echo "Save the synthesized plan to thoughts/plans/ for future reference."
# Cleanup
rm -f "$SCRATCH_DIR/gemini.pid" "$SCRATCH_DIR/codex.pid"
exit 0
the hook auto-saves raw council output to thoughts/research/ with timestamps. you can grep through old perspectives when you forget why you rejected an approach three weeks ago.
what the output looks like
when claude exits plan mode, it sees something like:
=== COUNCIL RESULTS ===
### Gemini's Plan
1. Use the existing auth middleware pattern from /src/app/core/security.py
2. Add OAuth provider config to settings.py
3. Create /src/app/services/oauth.py with provider implementations
...
### Codex's Plan
1. Implement OAuth flow in a new router /src/app/api/v1/endpoints/oauth.py
2. Store tokens in the existing Firebase setup
3. Add rate limiting to prevent abuse
...
=== END COUNCIL ===
Consider the above perspectives when finalizing your plan.
then claude synthesizes:
Agreement (all 3 models):
- Use existing auth middleware pattern
- Store tokens in Firebase
- Add rate limiting
Gemini's unique insight:
- Suggested abstracting providers for future additions
Codex's unique insight:
- Flagged token refresh race condition
Conflict: Router location
- Gemini: Add to existing auth router
- Codex: New dedicated oauth router
- Claude: Separate router for clarity
- Recommendation: New router, but share middleware
real example: rate limiting
task: "add rate limiting to the API endpoints"
claude's approach: middleware-based, redis for distributed state, per-user and per-IP limits.
gemini's approach: also middleware, but suggested slowapi library and pointed out a recent FastAPI best practice.
codex's approach: emphasized different limits for authenticated vs anonymous users, with patterns from popular repos.
the synthesis:
- all three agreed on middleware placement → high confidence
- gemini's library suggestion saved reinventing the wheel
- codex's auth/anon distinction was a blind spot for claude and gemini
- combined: better than any single model
graceful degradation
the council is advisory, not blocking. if gemini times out, claude continues. if codex fails, we work with what we have.
cat "$SCRATCH_DIR/gemini.md" 2>/dev/null || echo "(No response)"
you don't want planning held hostage by an API hiccup.
why this matters
- diverse perspectives early — catch bad architecture in planning (minutes) not implementation (days)
- confidence calibration — three models converge independently = meaningful signal
- unknown unknowns — each model has different training data, different code exposure. gemini might know a library update. codex might have seen this fail in a thousand repos.
- zero extra effort — automatic hooks. just use plan mode.
v3: superpowers + codex review gate
why i stopped using my own hooks
v1 and v2 worked. but maintaining bash scripts that parse transcripts, manage background processes, and handle timeouts across three LLM APIs is fragile. every time an API changed or claude code updated its hook format, something broke.
then i found superpowers.
what superpowers replaced
superpowers is a skill system for claude code built by jesse vincent. it installs as a plugin and gives claude a structured workflow for brainstorming, planning, debugging, testing, and verification — all the things my custom hooks were trying to do, but better.
here's what it replaced:
v1 sequential critique → superpowers brainstorming + planning skills. instead of claude writing a plan and then sending it to other models for review, superpowers changes how claude plans in the first place. the brainstorming skill uses socratic questioning — it probes your intent, surfaces assumptions, and presents multiple approaches in structured sections before you commit to anything. it's not "here's my plan, what do you think?" it's "here are three approaches with tradeoffs, which direction do you want?"
v2 council → mostly replaced, with a gap. the brainstorming skill gives you the diverse-perspectives-early benefit that council provided. claude explores multiple approaches and presents them for your input before committing. the gap: it's still one model doing the exploration. i haven't brought back /council to run gemini and codex in parallel during the superpowers brainstorm phase — that's on my list.
plan mode itself → replaced. superpowers effectively replaces claude code's built-in plan mode for me. the writing-plans skill creates detailed implementation plans with bite-sized tasks (2-5 minutes each), exact file paths, and verification steps. the executing-plans skill works through them with review checkpoints. it's more structured than what i was getting from raw plan mode + hook critiques.
the key skills i use daily:
| Skill | What it does |
|---|---|
brainstorming | Socratic design exploration before any code |
writing-plans | Detailed implementation plans with verification steps |
executing-plans | Works through plans with review checkpoints |
test-driven-development | RED-GREEN-REFACTOR enforcement |
systematic-debugging | Root-cause analysis before proposing fixes |
verification-before-completion | Evidence-based completion checks |
requesting-code-review | Structured review with severity tracking |
what superpowers didn't replace: the review gate
superpowers has a verification-before-completion skill that checks work before claiming done. it's good — it makes claude actually run tests and verify output before saying "done."
but it's still claude checking claude's own work. same model, same blind spots.
that's where the codex review gate comes in. it's a different model (codex/gpt) reviewing the actual diff after implementation. different training data, different biases, different things it notices.
the codex review gate
the review gate fires when you're about to mark work as done. codex reviews the actual changes — not the plan, the implementation.
you: /done
codex: [reviews diff, checks for drift, missed tests, security issues]
codex: "LGTM" → work marked done
codex: "ISSUES FOUND" → you see the issues before claiming completion
setup is one command:
/codex:setup --enable-review-gate
the codex plugin configures everything. no hooks to write, no scripts to maintain.
what the review gate catches
real examples from my recent sessions:
- test drift — plan said "test the error path for expired tokens." implementation had a test file but the error path test was a TODO comment.
- missing files — plan listed 4 files to create. only 3 existed. the 4th was referenced in imports but never written.
- silent failures — tests passed but were testing the mock, not the actual implementation. codex flagged the
vi.mockplacement issue.
these are exactly the failure modes from my execution outcomes — the Q:0/5 and Q:1/5 scores were almost always implementation drift, not bad plans.
why codex specifically
codex is genuinely good as both a model and a harness. it runs against the actual diff — it sees what changed, not what you said would change. it has codebase context and can verify claims ("did you actually add that test?").
a review gate check takes 10-20 seconds. small price for catching the kind of failures that used to cost hours.
how the current pipeline works
[superpowers brainstorm] → [superpowers plan] → [implementation w/ TDD] → [codex review gate] → done
- brainstorming skill — socratic exploration, multiple approaches presented
- writing-plans skill — detailed plan with file paths, verification steps
- executing-plans + TDD skills — implementation with review checkpoints
- codex review gate — different-model verification of the actual diff
superpowers handles the planning lifecycle. codex handles the final quality gate. they complement each other because they solve different problems: superpowers makes the process better, codex makes the output verifiable.
the evolution
| Version | Approach | Status |
|---|---|---|
| v1 | Custom bash hooks, sequential LLM critique | Retired — replaced by superpowers |
| v2 | Custom bash hooks, parallel council brainstorm | Mostly retired — superpowers brainstorming replaces this, but /council with parallel models is still on my list |
| v3 | Superpowers skills + codex review gate | Current |
the progression: hand-rolled bash scripts → structured skill system + purpose-built review tool. less maintenance, better results.
what's next
- bring back
/councilfor superpowers brainstorm — run gemini and codex in parallel during the brainstorming phase. superpowers gives you structured exploration from one model; council would add diverse perspectives from three. - close the feedback loop — feed review gate findings back into brainstorm prompts so the same class of drift doesn't recur
- more codex integration — codex as a rescue agent when claude gets stuck, not just as a reviewer
related
- superpowers — the skill system that replaced my custom hooks
- my overall ai coding workflow
- test-first enforcement. the validator script
- handoff. managing context across sessions
the lesson from v1 → v2 → v3: don't build infrastructure you can install. my custom hooks taught me what i needed. superpowers delivers it better. codex fills the gap that no single-model system can — a second pair of eyes on the actual output.
the best multi-model workflow isn't "throw models at every stage." it's "use the right tool at the right stage." superpowers for process. codex for verification. done.
< EOF